{kind=link}
Have you ever wondered how Netflix recommends movies and shows that you might like more accurately? Well, that is supervised machine learning at work. Businesses are using machine learning to solve complex predictive and classification problems, from predicting diseases to enabling self-driving cars.
Python has become a versatile tool for building and training supervised machine learning algorithms. It uses open-source machine learning libraries such as Sci-Kit Learn, TensorFlow, pandas, and many others for efficient data analysis and manipulation.
This simplified and practical guide will teach you about supervised machine learning, its different types, and supervised ML algorithms. Above all, you will learn how to implement these algorithms in Python.
To simplify things, here’s the Google Colab document you can follow along with this tutorial.
What is Supervised Machine Learning?
Supervised machine learning is a subset of machine learning in which we train models on a labeled dataset to predict output for previously unseen data.
For example, data for training an email spam detection system might include emails (input) and labels like spam or not (output).
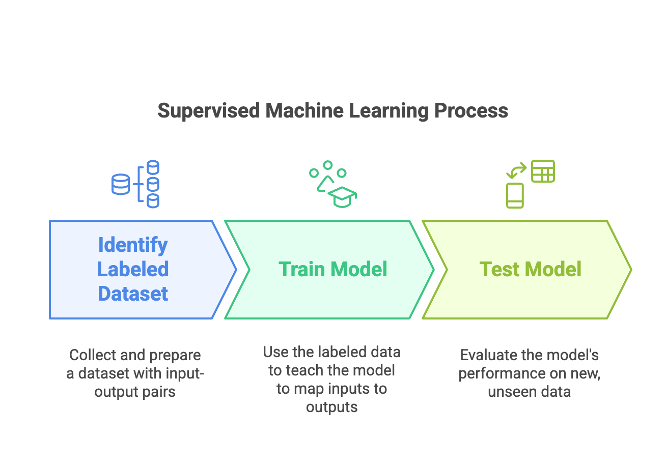
Labeled data is crucial for supervised machine learning, as the algorithm uses this data to identify the underlying patterns and predict the outcome for new, unseen data.
Also Read: GitHub Copilot Review: Is It Worth Your Developer Vibes?
Different Types of Supervised Machine Learning
There are two types of supervised machine learning: Classification and Regression.
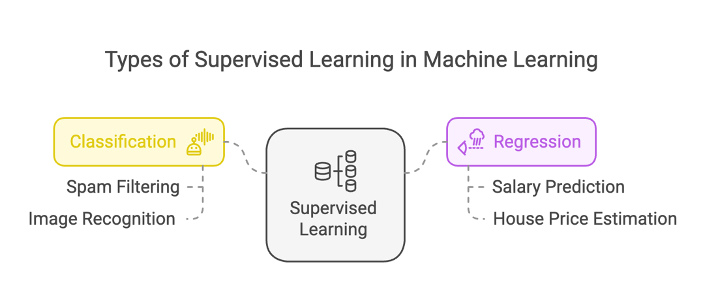
1. Classification
Classification in supervised machine learning involves training a model to categorize data into predefined labels. The model then uses the labelled data to predict the label of new, unseen data.
A classic example of classification is the spam filter system. Most email providers use classification algorithms to determine whether an email is spammy. It analyses various data points, such as information about each email, subject line, body, etc., to classify an email as spam.
2. Regression
In Regression, we train the supervised machine learning algorithm to predict continuous numerical values based on input features.
Predicting stock prices is a tricky and challenging task in the trading world. Here, you can analyze data points (features) such as opening and closing prices, trading volume, economic indicators, etc., to train and build a regression model to predict stock prices.
Different Steps in Supervised Machine Learning
Before moving forward, let’s understand the core steps of implementing a supervised machine learning project.
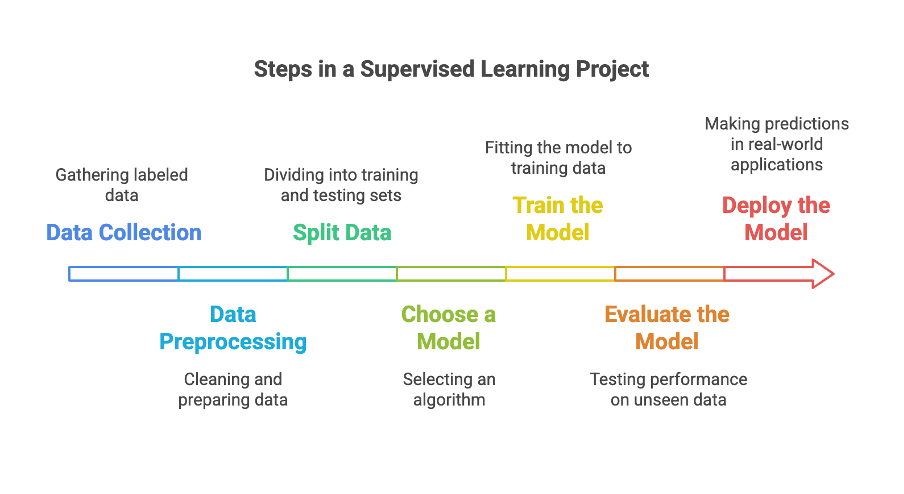
1. Data Collection
In this first step, you must collect labeled data for the supervised ML project. You can use publicly available datasets from Kaggle or the UCI Machine Learning Repository for practice.
However, ensure that each row in the selected dataset contains features (inputs) and corresponding target labels (outputs).
2. Data Preprocessing
The next step is to clean and prepare the data for model training. Handle the missing values in your dataset by removing those rows or filling the gaps using the mean or median for numerical data.
For categorical data, you can choose the most frequently used category. The primary goal is to ensure the dataset is clean and ready for analysis.
3. Splitting Data
Divide the dataset into training and testing subsets to evaluate the model’s performance. In most cases, you can divide the data into 80% for training and 20% for testing.
However, this can vary depending on your data size. The main goal is to train the model on one portion and test its accuracy on another.
4. Choosing the Right Machine Learning Model
Choosing the correct supervised machine learning algorithm depends on the problem you are trying to solve. You can use classification algorithms like Random Forest for tasks like predicting categories.
To determine continuous outcomes, you can use regression algorithms like Gradient Boosting. The best way is to experiment with multiple algorithms to find the best option.
5. Training the Model
After choosing a model, the next step is to train it with your dataset. During this training phase, models identify the underlying patterns of the data to make predictions.
This process involves optimizing internal parameters, such as weights in logistic regression or decision thresholds in a decision tree.
6. Supervised Machine Learning Model Evaluation
We will test the model on the unseen data to measure its generalization ability. You can use the following metrics to evaluate the performance of any supervised machine learning:
- Classification: Accuracy, precision, F-1 score, recall, and confusion matrix.
- Regression: Mean Absolute Error (MAE), Mean Squared Error (MSE), or R-squared.
7. Deploying the Supervised ML Model
After rigorous training and testing, you can deploy the ML model for real-world applications.
In this step, the supervised ML model is integrated into a software system that receives new inputs to make predictions.
Now that you understand the steps involved in supervised machine learning, let’s move ahead and implement it using Python.
Also Read: 5 Top AI-Powered VS Code Extensions That Every Developer Needs
Different Types of Supervised Machine Learning Algorithms
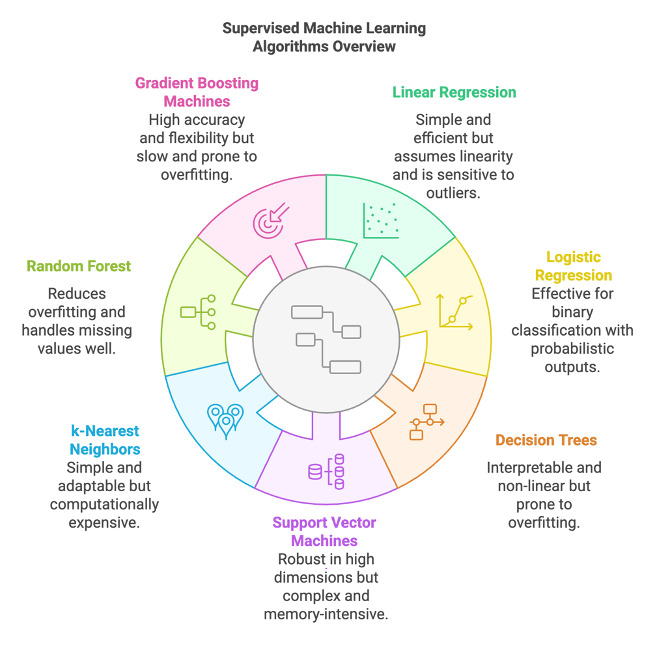
- Linear Regression: We can use linear Regression to predict outcomes based on input variables. However, it assumes a linear relationship between them and might not provide accurate results in real-world applications.
- Logistic Regression: This algorithm best works for binary classification tasks where you want to predict “yes” or “no.” It also assumes a linear relationship between inputs and outcomes, which affects its efficiency for non-linear data sets.
- Decision Trees: We split the data into branches to make predictions. This method is handy for solving classification and regression problems, such as predicting customer churn. However, its main drawbacks include overfitting and sensitivity to noisy data.
- Support Vector Machines (SVMs): Finding the optimal hyperplane to separate data into classes works. However, it can be computationally expensive and struggle with large datasets.
- K-Nearest Neighbours: This ML algorithm finds the ‘k’ closest data points to a query and predicts the outcome based on their average value.
- Random Forest: This ensemble learning algorithm combines multiple decision trees to improve accuracy. Due to their complexity, Random Forests can be computationally expensive and harder to interpret.
- Gradient Boosting Machines: This ensemble learning algorithm uses several weak learners to create a predictive model. It can be efficiently utilized for financial predictions or customer behaviour modelling.
Implementing Supervised Machine Learning in Python
Enough of the theory; let’s now see how to implement various supervised machine-learning algorithms using Python.
We will use the Iris dataset, which is pretty neat and beginner-friendly..
Step 1: Understanding the Iris Dataset
The Iris dataset contains 150 observations of iris flowers, with four features: Sepal length, Sepal width, Petal length, and Petal width.
Each row is labelled with one of three species: Iris setosa, Iris versicolor, or Iris virginica. Our goal is to classify the species of an iris flower based on its features.
Let’s load and take a look at the data.
import pandas as pd from sklearn.datasets import load_iris # Load dataset iris = load_iris() df = pd.DataFrame(data=iris.data, columns=iris.feature_names) df['species'] = iris.target df.head()
Output:
Step 2: Data Preprocessing
We’ll ensure the data is clean and ready before feeding it into models. The Iris dataset’s data is already clean, but as mentioned earlier, you might require additional heavy lifting for other datasets before training the model.
from sklearn.preprocessing import StandardScaler # Normalize the features scaler = StandardScaler() X = scaler.fit_transform(df.iloc[:, :-1]) y = df['species']
Here’s a summary of our preprocessing steps:
- Normalize numerical features: Standardize feature values for better model performance.
- Encode labels: The species column is already numeric, so no further action is needed here.
Step 3: Splitting the Data
We’ll now split the dataset into training and testing subsets.
A typical split is 80% for training and 20% for testing.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Step 4: Applying Machine Learning Models
Let’s now import supervised machine learning models into our Python code.
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
# Initialize models
models = {
"Logistic Regression": LogisticRegression(),
"KNN": KNeighborsClassifier(),
"Decision Tree": DecisionTreeClassifier(),
"Random Forest": RandomForestClassifier(),
"Linear SVM": SVC(kernel='linear'),
"Non-Linear SVM": SVC(kernel='rbf')
}
Step 5: Training and Testing
We will train each model on the training data and evaluate it based on the testing data.
Here’s the complete Python code in action.
Output
Logistic Regression: 100.00% accuracy KNN: 100.00% accuracy Decision Tree: 100.00% accuracy Random Forest: 100.00% accuracy Linear SVM: 96.67% accuracy Non-Linear SVM: 100.00% accuracy
As you can see, almost all supervised ML algorithms worked exceptionally well on the Iris dataset. The main reason is that the Iris dataset is relatively small and organized.
However, in real-world applications, you would need to work with incomplete datasets and focus more on feature engineering and fine-tuning these models to achieve accurate performance.
Conclusion
Supervised machine learning is taking the world by storm, allowing data scientists and ML practitioners to solve complex problems.
From predicting stock prices to diagnosing diseases, supervised machine learning provides algorithms to solve classification and regression problems more accurately and efficiently.
However, Python makes it accessible to everyone thanks to its extensive support for libraries like Sci-Kit Learn, NumPy, and more.
The best part is that developers don’t have to understand the mathematics involved in these complex ML algorithms.